대규모 자료에서 패턴 학습
모델은 공개 자료, 라이선스 자료, 사람이 만든 예시 등 다양한 데이터에서 언어 패턴을 학습할 수 있습니다. 문장을 그대로 저장해 꺼내는 방식이 아니라, 토큰과 문맥 사이의 통계적 관계를 수많은 매개변수에 반영합니다.
핵심: 어떤 표현이 어떤 문맥에서 함께 나타나는지 예측하도록 훈련됩니다.
심화 설명 펼치기: 단어를 숫자로 바꾸는 마법 (Embedding) ▼
모델은 입력된 토큰을 숫자 벡터로 바꿔 계산합니다. 이를 임베딩이라고 하며, 이후 여러 층을 지나면서 같은 토큰도 주변 문맥에 따라 서로 다른 표현으로 바뀝니다.
- 단순화한 임베딩 공간에서는 비슷한 쓰임을 가진 토큰이 가까운 방향에 놓일 수 있습니다. 실제 최신 LLM의 내부 표현은 문맥과 층에 따라 계속 달라집니다.
- 수식 맛보기: $$ \text{Sim}(A, B) = \frac{A \cdot B}{\|A\| \|B\|} $$ 이 수식은 두 단어 A와 B가 얼마나 비슷한지 계산하는 '코사인 유사도' 공식입니다. 각도가 좁을수록(1에 가까울수록) 비슷한 단어라는 뜻입니다.
단순화한 의미 관계도
설명을 위한 2차원 개념도이며 실제 모델 내부 좌표가 아닙니다.
다음에 올 토큰 예측 확률
빈칸 채우기 (토큰 예측)
LLM의 핵심은 '검색'이 아니라 '예측'입니다. 하지만 AI는 우리가 쓰는 '단어'가 아닌 '토큰(Token)'이라는 조각 단위로 언어를 이해합니다.
🔹 토큰이란? 모델이 텍스트를 처리하는 조각입니다. 단어 전체, 단어의 일부, 문장부호, 바이트 조각 등이 될 수 있으며 나누는 방식은 모델마다 다릅니다. 한글 토큰이 항상 글자나 형태소와 일치하는 것은 아닙니다.
🔹 학습 자료: 모델은 공개 자료, 라이선스 자료, 사람이 만든 예시 등 다양한 데이터에서 패턴을 학습할 수 있습니다. 정확한 구성과 토큰 수, 어휘 사전 크기는 모델마다 다르고 모두 공개되지는 않습니다.
모델은 앞의 문맥을 바탕으로 다음 토큰의 확률 분포를 계산하고, 설정된 방식에 따라 토큰을 하나씩 생성합니다.
심화 설명 펼치기: 샘플링 설정 (Temperature, Top-p) ▼
모델은 다음 토큰 후보의 확률 분포에서 결과를 선택합니다. 제품과 모델에 따라 샘플링 설정을 직접 조절할 수 있거나, 권장 기본값이 고정되어 있을 수 있습니다.
Temperature(온도)는 후보 확률 분포의 평평한 정도를 조절하는 대표적 설정입니다.
- 온도가 낮으면: 후보 분포가 좁아져 출력이 비교적 반복 가능해질 수 있습니다.
- 온도가 높으면: 후보 분포가 넓어져 표현의 다양성이 커질 수 있습니다.
- 중요: 낮은 온도가 사실 정확성을 보장하지 않습니다. 최신 추론 모델은 기본 설정이 권장되는 경우가 많고, 조절 범위도 제품마다 다릅니다.
2. Top-p (Nucleus Sampling):
확률 순위가 아니라 누적 확률로 자르는 방식입니다.
예를 들어 Top-p = 0.9라면, 상위 1등부터 확률을 더해나가다가 90%가 채워지는 순간 그 뒤의 후보들은 모두 탈락시킵니다.
→ 선택 후보의 범위를 바꾸는 방식이며, 환각을 막거나 정답을 보장하는 장치는 아닙니다.
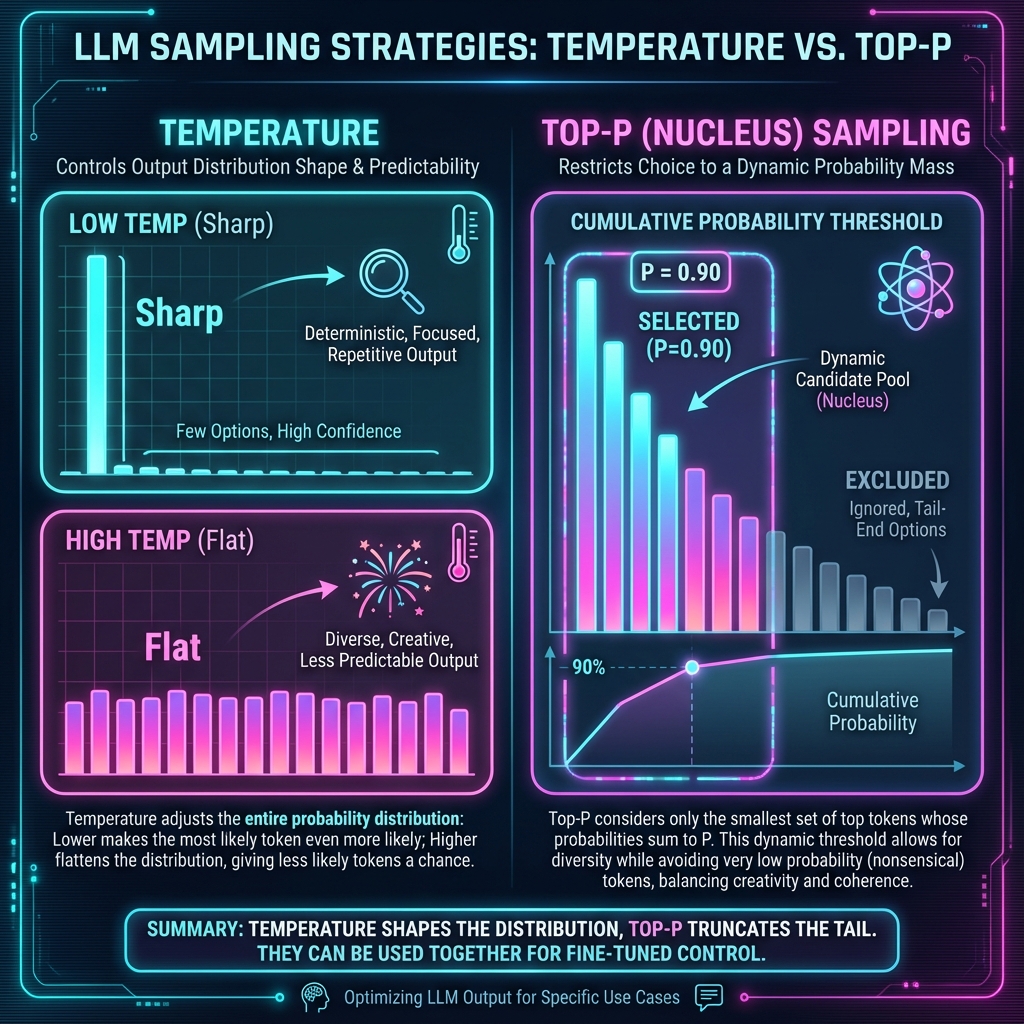
Temperature(분포 모양 조절) vs Top-P(꼬리 자르기) 시각화
수식 맛보기: $$ P(t) = \text{softmax}\left(\frac{\text{점수}}{\text{온도}}\right) $$ 온도(T)로 점수를 나누기 때문에, 온도가 높을수록 점수 차이가 줄어들어(평평해져) 아무거나 뽑힐 확률이 늘어납니다.
실시간 확률 분포 변화
* 슬라이더를 움직여보세요! 파란색은 선택 가능한 후보(Nucleus), 회색은 탈락한 후보입니다.
🧩 토크나이저 체험 (Tokenizer Simulator)
AI가 문장을 어떻게 조각내서 보는지 체험해보세요. (교육용 시뮬레이션으로, 실제 모델의 복잡한 토크나이저와는 다를 수 있습니다.)
실제 분할 결과는 모델마다 다릅니다. OpenAI가 제공하는 도구에서 지원 모델의 토큰 분할을 별도로 확인할 수 있습니다.
OpenAI 토크나이저 열기눈치 100단 (문맥 파악)
어텐션(Attention)은 현재 토큰을 처리할 때 문맥 안의 다른 토큰을 얼마나 참고할지 계산하는 핵심 메커니즘입니다. 그래서 같은 표기의 토큰도 주변 문맥에 따라 다른 내부 표현을 가질 수 있습니다.
상황 A: "나는 배가 고파서 식당에 갔다."
상황 B: "나는 배를 타고 바다로 나갔다."
심화 설명 펼치기: 집중해야 할 곳을 찾는 Attention ▼
AI가 문장을 이해하는 방식은 도서관에서 책을 찾는 것과 비슷합니다.
1. 세 가지 역할 (Q, K, V):
- Query (질문): "내가 지금 찾고 싶은 내용은 뭐야?" (검색어)
- Key (색인): "이 책은 어떤 내용을 담고 있어?" (책 제목/라벨)
- Value (내용): "그 책의 실제 내용은 뭐야?" (책 본문)
2. 작동 원리 (Attention Score):
AI는 검색어(Q)와 책 제목(K)이 얼마나 비슷한지 계산합니다. (이것을 '내적'이라고 합니다.)
비슷할수록 점수가 높아지고, 점수가 높은 책의 내용(V)을 더 많이 참고해서 문맥을 파악합니다.
수식으로 보면:
$$ \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V $$(Q와 K를 곱해서 유사도를 구하고, 그 비율만큼 V를 섞는다)
단어 '배'에 대한 AI의 인식 변화
후학습과 정렬
사전학습만 마친 기본 모델은 사용자 지시를 안정적으로 따르지 못할 수 있습니다. 지도학습, 선호 최적화, 안전 훈련과 평가 등을 거쳐 지시 준수와 유용성·안전성을 높입니다. 그래도 오류와 편향 가능성은 남습니다.
기본 모델 (Base Model)
다음 토큰 예측에 최적화되어 사용자 지시를 안정적으로 따르지 못할 수 있음
지시 조정된 모델
도움됨·안전함·지시 준수 향상을 목표로 하지만 여전히 오류 가능
심화 설명 펼치기: 지시 준수와 안전성을 높이는 후학습 ▼
사람이 만든 예시와 선호 신호 등을 이용해 기본 모델의 응답 방식을 조정합니다. 제품마다 사용하는 방법과 순서는 다릅니다.
- SFT (지도 학습): 선생님이 직접 "질문에는 이렇게 대답해"라고 모범 답안을 보여줍니다.
-
선호 최적화·RLHF:
- 여러 응답 중 더 나은 응답에 대한 선호 자료를 모읍니다.
- 선호를 직접 최적화하거나 보상 모델을 학습합니다.
- 안전성·유용성 평가로 실제 개선 여부와 부작용을 반복 점검합니다.
개념을 설명하기 위한 예시 수치이며 실제 성능 측정값이 아닙니다.
의료 문서에서 반드시 검증할 항목
과제·모델·자료·도구 사용에 따라 달라집니다.
주의: 할루시네이션 (환각, Hallucination)
AI는 확률적으로 출력을 만들기 때문에, 가끔 없는 사실을 그럴듯하게 생성합니다. 이를 '할루시네이션'이라고 합니다. 이는 의도적인 거짓말이 아니며, 답변의 자신감만으로 정확성을 판단할 수 없습니다.
작동 원리를 이해하셨다면, 이제 본격적인 실습으로 넘어갑니다.
Module 1: 역할과 안전 경계 →